DINORANKCLIP: DINOv3 Distillation and Injection for Vision-Language Pretraining with High-Order Ranking Consistency
基本信息
- arXiv ID: 2605.06592v1
- 作者: Shuyang Jiang, Nan Yu, Yiming Zhang et al.
- 发布日期: 2026-05-07
- 分类: cs.CV, cs.AI, cs.LG
- PDF: arXiv PDF
关键图示
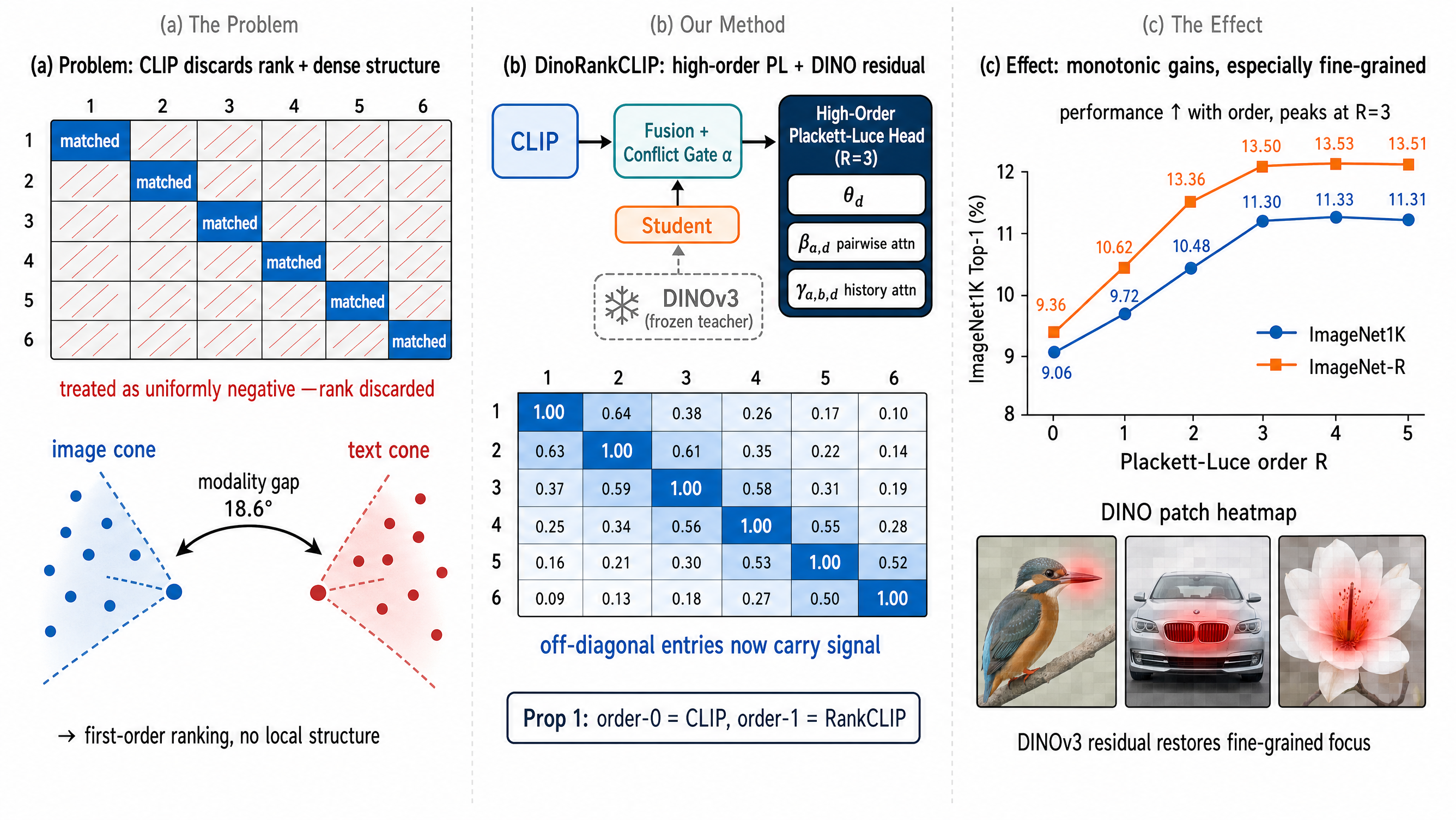


摘要
English
Contrastive language-image pretraining (CLIP) suffers from two structural weaknesses: the symmetric InfoNCE loss discards the relative ordering among unmatched in-batch pairs, and global pooling collapses the visual representation into a semantic bottleneck that is poorly sensitive to fine-grained local structure. RANKCLIP partially addresses the first issue with a list-wise Plackett-Luce ranking-consistency loss, but its model is strictly first-order and inherits the second weakness untouched. We propose DINORANKCLIP, a pretraining framework that addresses both jointly. Our principal contribution is injecting a frozen DINOv3 teacher into the contrastive trunk through a dual-branch lightweight student and a multi-scale fusion module with channel-spatial attention, a self-attention refiner, and a conflict-aware gate that preserves the cross-modal alignment up to first order. Complementarily, we introduce a high-order Plackett-Luce ranking model in which the per-position utility is augmented with attention-parameterised pairwise and tuple-wise transition terms; the family contains CLIP and RANKCLIP as nested zero-order and first-order special cases, and the optimal order on every benchmark is $R^*=3$. The full empirical study – order sweep, Fine-grained Probe on five datasets, four-node Modality-Gap analysis, six-variant Fusion ablation – fits in 72 hours on a single eight-GPU H100 node and trains entirely on Conceptual Captions 3M. DINORANKCLIP consistently outperforms CLIP, CyCLIP, ALIP, and RANKCLIP under matched compute, with the largest relative gains on the fine-grained and out-of-distribution evaluations that most directly stress local structural reasoning.
中文
对比语言图像预训练(CLIP)存在两个结构性弱点:对称的 InfoNCE 损失丢弃了不匹配的批内对之间的相对顺序,全局池化将视觉表示折叠成对细粒度局部结构不敏感的语义瓶颈。 RANKCLIP 通过列表方式的 Plackett-Luce 排名一致性损失部分解决了第一个问题,但其模型是严格的一阶模型,并且继承了第二个弱点。我们提出了 DINORANKCLIP,这是一个联合解决这两个问题的预训练框架。我们的主要贡献是通过双分支轻量级学生和具有通道空间注意力的多尺度融合模块、自注意力细化器和冲突感知门将冻结的 DINOv3 教师注入到对比主干中,该模块将跨模态对齐保留到一阶。作为补充,我们引入了高阶 Plackett-Luce 排序模型,其中每个位置的效用通过注意参数化的成对和元组转换项得到增强;该系列包含 CLIP 和 RANKCLIP 作为嵌套的零阶和一阶特殊情况,并且每个基准上的最佳阶数为 $R^*=3$。完整的实证研究——顺序扫描、五个数据集上的细粒度探测、四节点模态差距分析、六变体融合消融——在单个八 GPU H100 节点上花费 72 小时完成,并完全在 Conceptual Captions 3M 上进行训练。在匹配计算下,DINORANKCLIP 的性能始终优于 CLIP、CyCLIP、ALIP 和 RANKCLIP,在最直接强调局部结构推理的细粒度和分布外评估方面具有最大的相对增益。
相关概念
核心贡献
- 冲突感知 DINOv3 注入:通过双分支 ViT-Tiny 学生蒸馏 DINOv3 的 Gram 矩阵和关系距离目标,再经多尺度融合模块(1D 空间金字塔池化 + 通道-空间注意力 + 自注意力细化器 + 冲突感知门)注入对比主干,将密集局部结构作为残差信号叠加而不破坏跨模态对齐(命题 1 证明保留至一阶)。
- 高阶 Plackett-Luce 排序模型:将 RANKCLIP 的一阶排序一致性推广到高阶,引入注意力参数化的成对转换项 β_{a,d} 和元组转换项 γ_{a,b,d},该族包含 CLIP(零阶)和 RANKCLIP(一阶)作为嵌套特例,所有基准上最优阶数 R*=3。
- 可复现的全套实验:在单节点 8×H100 GPU 上 72 小时完成,仅使用 Conceptual Captions 3M 训练,包括阶数扫描、5 个数据集的细粒度探针、四节点模态间隙分析和六变体融合消融。
- 匹配计算下的一致领先:在零样本分类、细粒度检索和分布外评估上全面超越 CLIP、CyCLIP、ALIP 和 RANKCLIP。
方法概述
DINORANKCLIP 在 RANKCLIP 基础上进行了两项协调扩展。主贡献是冲突感知 DINOv3 教师注入:先离线预提取 DINOv3 特征并 PCA 降至 256 维,训练时通过双分支小模型蒸馏 Gram + 关系距离目标,再经多尺度融合模块与 CLIP 全局嵌入门控组合。第二贡献是高阶排序头:用小型注意力头学习成对和元组转换项,将排序监督从单点效用推广到多步邻居关系。完整损失包含 CLIP、排序一致性、蒸馏项和 L1 正则化门控。
实验结果
在 ImageNet-1K、ImageNet-R、ImageNet-Sketch、ObjectNet 等标准基准上,DINORANKCLIP 一致优于对比方法。细粒度探针(5 个数据集)显示最大相对增益集中在最需要局部结构推理的任务上。模态间隙分析(四节点)验证了 DINOv3 残差缩小了图文表征间的模态差距。融合消融(六变体)确认了多尺度 SPP + 通道-空间注意力 + 自注意力细化器 + 冲突感知门各组件的必要性。所有基准上最优 Plackett-Luce 阶数均为 R*=3。
局限性与注意点
- 依赖预提取的 DINOv3 特征,若更换教师模型需重新提取;PCA 降维可能丢失部分几何信息。
- 训练受限在 CC3M(3M 图文对),未验证在更大规模数据(如 LAION-400M)上的可扩展性。
- 高阶排序头的注意力参数在批大小较小时可能存在统计不稳定性。
- 冲突感知门虽保留一阶对齐,但更高阶的跨模态一致性未被显式保证。
相关概念
关于视觉-语言预训练和排序一致的更多文献,参见 多模态学习、基准评估、AI安全与对齐 和 图神经网络。
导入时间: 2026-05-09 06:00 来源: arXiv Daily Wiki Update 2026-05-09