PSK at SemEval-2026 Task 9: Multilingual Polarization Detection Using Ensemble Gemma Models with Synthetic Data Augmentation
基本信息
- arXiv ID: 2605.05159v1
- 作者: Srikar Kashyap Pulipaka
- 发布日期: 2026-05-06
- 分类: cs.CL, cs.AI, cs.LG
- PDF: arXiv PDF
关键图示
摘要
English
We present our system for SemEval-2026 Task 9: Multilingual Polarization Detection, a binary classification task spanning 22 languages. Our approach fine-tunes separate Gemma~3 models (12B and 27B parameters) per language using Low-Rank Adaptation (LoRA), augmented with synthetic data generated by a large language model (LLM). We employ three synthetic data strategies (direct generation, paraphrasing, and contrastive pair creation) using GPT-4o-mini, with a multi-stage quality filtering pipeline including embedding-based deduplication. We find that per-language threshold tuning on the development set yields 2 to 4\% F1 improvements without retraining. We also use weighted ensembles of 12B and 27B model predictions with per-language strategy selection. Our final system achieves a mean macro-F1 of 0.811 across all 22 languages, ranking 2nd overall of the participating teams, with 1st place finishes in 3 languages and top-3 in 8 languages. We also find that alternative architectures (XLM-RoBERTa, Qwen3) that showed strong development set performance suffered 30 to 50\% F1 drops on the test set, highlighting the importance of generalization.
中文
我们展示了用于 SemEval-2026 任务 9 的系统:多语言极化检测,这是一项涵盖 22 种语言的二元分类任务。我们的方法使用低秩适应 (LoRA) 微调每种语言的单独 Gemma~3 模型(12B 和 27B 参数),并通过大型语言模型 (LLM) 生成的合成数据进行增强。我们使用 GPT-4o-mini 采用三种合成数据策略(直接生成、释义和对比对创建),并具有多级质量过滤管道,包括基于嵌入的重复数据删除。我们发现,在开发集上对每种语言的阈值进行调整可在无需重新训练的情况下产生 2 至 4% 的 F1 改进。我们还使用 12B 和 27B 模型预测的加权集成以及每种语言的策略选择。我们的最终系统在所有 22 种语言中实现了 0.811 的平均宏 F1,在参赛团队中排名第二,其中 3 种语言获得第一名,8 种语言获得前三名。我们还发现,表现出强大开发集性能的替代架构(XLM-RoBERTa、Qwen3)在测试集上的 F1 下降了 30 到 50%,这凸显了泛化的重要性。
核心贡献
- 提出了针对 SemEval-2026 Task 9(多语言极化检测,22 种语言)的竞赛系统,在所有参赛团队中排名第 2,平均宏 F1 达 0.811,其中 3 种语言获第 1 名、8 种语言获前 3 名。
- 系统性地比较了三种合成数据增强策略——直接生成(50%)、标签保持释义(30%)和对比对创建(20%)——使用 GPT-4o-mini 生成约 1,000 条/语言的合成样本。
- 通过按语言的阈值调优(在开发集上搜索阈值 t ∈ {0.3, …, 0.7}),在不重新训练的情况下实现了 2-4% 的 F1 提升。
- 重要发现:在开发集上表现良好的替代架构(XLM-RoBERTa、Qwen3)在测试集上 F1 骤降 30-50%,凸显了泛化能力而非开发集性能才是成功关键。
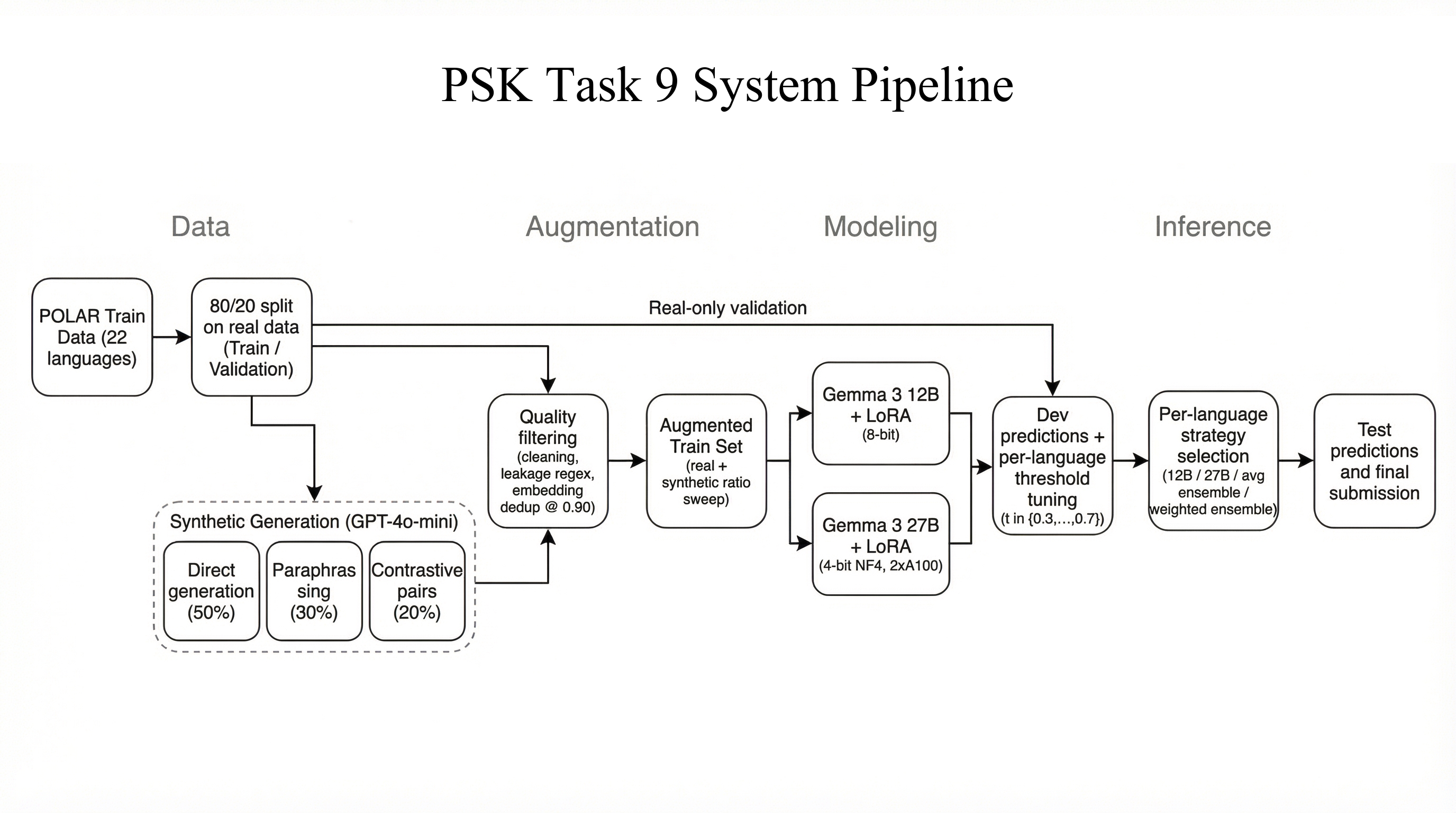
方法概述
系统基于 Google Gemma 3 系列模型,使用 LoRA 对每种语言分别微调。两个模型规模:(a) Gemma 3 12B:8-bit 量化,单 A100 GPU,LoRA rank=16,学习率 5×10⁻⁵,3 个 epoch;(b) Gemma 3 27B:4-bit NF4 量化,跨 2 个 A100 GPU,梯度检查点。
数据增强分三步:(1) 直接生成:在 5 个文化相关主题类别(政治、民族/种族、宗教、社会阶层、国际关系)下以目标语言原生生成样本;(2) 标签保持释义:对真实样本进行 temperature=0.7 的释义,过滤余弦相似度 >0.90 的样本;(3) 对比对创建:在同一主题上生成极化/非极化最小对。质量过滤包括基于嵌入的重复数据删除(paraphrase-multilingual-MiniLM-L12-v2,阈值 0.90)、往返翻译一致性检查(阈值 0.70)和标签泄漏检测。
实验结果
- 主要结果(Table 1):最终提交在 22 种语言上平均宏 F1 为 0.811。单 Gemma-12B 最优阈值基线为 0.797;集成+阈值策略提升至 0.811。
- 合成数据比例消融(Table 2):Gemma 3 12B 在 30% 合成数据比例下达到最优开发集 F1(0.822),而 0% 基线为 0.812、50% 为 0.819,表明过多合成数据反而有害。
- 架构对比:混合 XLM-RoBERTa 和 Qwen3 的替代提交仅获平均 F1 0.665,远低于 Gemma 系统。
- 集成+阈值策略:为每种语言从 {12B solo, 27B solo, 平均集成, 加权集成} 中选择最优策略,加权集成中 w ∈ {0.3, 0.4, 0.6, 0.7}。
局限性与注意点
- 竞赛报告格式:作为 SemEval 系统描述论文,主要指标来自竞赛提交,内部实验仅在开发集上进行且不可重复验证测试集结果。
- 单参与者团队:系统设计决策受个人计算资源限制(2×A100),更大规模的集成或模型可能进一步提升。
- GPT-4o-mini 依赖:合成数据质量受生成模型能力限制,不同 LLM 的增强效果可能不同。
- 无多语言联合训练:按语言独立训练可能损失跨语言迁移的潜在收益。
相关概念
导入时间: 2026-05-07 06:01 来源: arXiv Daily Wiki Update 2026-05-07